I collect some of Apache Kafka usage in our team and write an internal post in Chinese. And I would like to pull the fundamental part into this post.
重要配置
Producer
生产者有很多可以配置的参数,大部分有合理的默认值,详情可以参考 Kafka 的文档。这里摘录了部分会影响生产环境中数据正确性的关键参数,并进一步解释如下。
| parameters | description |
|---|---|
| acks | 指定有多少个分区副本确认收到消息,生产者才会认为消息写入是成功的。 如果 ack = 0, 那么生产者在成功写入消息之前不会等待任何来自服务器的响应。假如消息发送过程中出现问题,导致服务器没有收到消息,生产者也无从得知,消息也会丢失。这种模式适合高吞吐量但对可靠性没有很高要求的场景(例如埋点数据的收集)但由于不需要等待服务器的响应,所以能够达到很高的吞吐量。(注意此时 retries 参数也不会起作用) 如果 ack = 1, 那么只要集群的 Leader 收到消息,生产者就认为服务器成功接收消息。如果消息无法达到首领节点,那么生产者会收到错误响应并进行重试。但这里可能出现的问题是,如果一个没有收到消息的节点在旧首领下线以后成为新的首领,消息还是会丢失。 如果 ack = all, 当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。这种模式是最为安全的,适合严格要求消息不能丢失的情况(例如支付、订单等相关消息)。然而由于要等待所有节点接收消息,所以延迟会比 ack = 1 时更高。 |
| retries | 决定 Producer 在临时性的错误下的重试次数,如果达到这个次数, Producer 会放弃重试并返回错误。每次重试之间的间隔,也可以通过 retry.backoff.ms 来配置。重试次数和重试间隔的乘积,应该大于一个常规的节点崩溃并回复的所需时间(例如所有分区选举出首领需要多少时间),以避免 Producer 过早放弃重试。一般情况下,我们在代码中只需要处理那些无法通过重试成功发送的错误,或重试次数超出上限以后的情况。 |
| linger.ms | Producer 会在 batch 被填满或者当前 batch 已经等待了 linger.ms 时,把 batch 中的所有消息一起发送出去。对于吞吐量较小的主题,这个值会影响消息的延迟。 |
| max.in.flight.requests.per.connection | 指定 Producer 在收到服务器响应之前可以发送多少消息。默认为5,提高此值可以提高吞吐量。但当值大于1时,在发送出现失败后重试时,将有几率无法保证消息按照发送的顺序写入服务器。在高吞吐量且无需关心数据顺序(例如日志或埋点记录)时,可适量提高。 |
| request.timeout.ms | Producer 在发送数据时等待服务器返回响应的时间 |
| timeout.ms | 指定 broker在等待同步副本返回消息确认的时间(与 acks 配置相互作用),如果在指定时间内没有收到同步副本的确认,broker会抛出错误。 |
| enable.idempotence | 设置为true时,Producer会保证消息只发送一次。设置为 False 时,重试就可能会引起多条数据发送到集群中。注意, enabling idempotence 要求 max.in.flight.requests.per.connection = 1 且 retries > 0 且 acks = ‘all’ |
Consumer
| parameters | description |
|---|---|
| fetch.min.wait.ms | 用于描述broker的等待时间,默认是500ms。如果没有足够的数据(fetch.min.bytes)流入,那么消费者会等待该参数指定的时间,然后返回所有可用的数据 |
| max.partition.fetch.bytes | 指定分区返回给消费者的最大字节数,默认为1MB。 KafkaConsumer.poll() 方法从每个分区里面返回的记录,不会超过配置中返回的字节数。如果一个主题有20个分区、5个消费者,那么每个消费者需要至少4MB的可用内存来接收记录。 |
| session.timeout.ms | consumer 与 coordinator 之间 session 超时时间,heartbeat request 将刷新此 timeout。如果 coordinator 发现 session 超时,将触发 rebalance |
| enable.auto.commit | 如果设置为 true,那么 poll 方法中接收到的最大偏移量就会被提交。提交间隔由 auto.commit.interval.ms 控制。自动提交是在轮询里进行的,假如每次在轮询时会检查是否改提交偏移量,如果是 |
| max.poll.records | 控制单次轮询处理的记录数 |
| max.poll.interval.ms | consumer 两次 poll 消息之间的最大间隔时间,poll request 将刷新此 timeout。如果 consumer 发现两次 poll 中间间隔时间超出此值,将主动发出 leave group 请求,该请求会使得此 consumer 离开所在的 consumer group,并触发 rebalance (注:如果 consumer 主动离开所在的 consumer group, 那么将会暂停 heartbeat request 的发送,下一次 poll 发生时会尝试重新加入 group) 同时改值也代表着 rebalance timeout,在一次 rebalance 中,如果在该时间内 consumer 未 join group,那么 consumer 将被认为离开了 group |
| heartbeat.interval.ms | consumer 两次发起 heartbeat 请求之间的间隔。该请求会刷新 session timeout 时间。如果 coordinator 发起了 rebalance,consumer 会通过该请求得知 rebalance 的发生,并发送 join group request 加入该 group |
可靠性
在讨论消息系统的可靠性时,要先考虑两个问题:
- 是否需要保证消息的可靠发送和消费,不丢数据。
- 是否需要保证消息的发送和业务数据的一致性 (一般是最终一致性,不要发送错误/不一致的数据)
假如 1 的答案为「是」,那么请继续阅读「Producer 可靠性 / Consumer 可靠性」章节;假如 2 中的答案为「是」,可以参考「事务型消息」章节来进行处理。
Producer 可靠性
Producer 需要处理的错误包括两部分:Producer 可以自动处理的错误 / Producer 无法自动处理,需要开发者单独处理的错误。
Producer 可以自动处理的错误,依赖于 Kafka 集群的自愈机制,例如 Leader Election / 网络问题。在这些情况下,Kafka 是可以在几秒到几十秒之间得到解决。而假如返回「INVALID_CONFIG」/ 「认证错误」之类的错误,那就不是重试可以解决的了,此时需要开发者单独处理。
大部分情况下,我们希望不丢失消息,那么最好让 Producer 在遇到可重试错误时能够保持重试,这样开发者就不需要加入额外手段去处理这些问题。
重试的过程中,Producer有一定可能向 broker 写入不止一条的消息:例如由于网络原因,消息实际已经写入,但 Broker 没有在超时时间内返回确认给 Producer ,那么 Producer 就会重试。但如下文所述,假如 Consumer 本身或业务本身可以做到消息消费的幂等性,那 Producer 就可以放心地使用内置的重试机制来重发消息。
Consumer 可靠性
在服务重启的时候,Consumer 就会有一段时间无法工作,或引起 re-balance,在这个过程中 Kafka 是如何保证消息会被一定可以被消费的呢?
Consumer 设置中最重要的一个参数,就是 enable.auto.commit。对可靠性有要求的业务,强烈建议将这个偏移量设置为手动提交。并在业务代码中贯彻以下的几个思想。
- 先处理,后提交偏移量。
- 若处理失败,留存消息进行补偿处理或报警(不阻塞后续消费),提交偏移量。
- 对消息的处理支持幂等。
Consumer Rebalance
子系统之间的交互大量的依赖于消息组件 Kafka 的支持。由此引发的一个问题是,当同一个 consumer group 中的机器集群的某一台机器宕机后,Kafka 以何种机制触发 rebalance,在多长的时间内可以将宕机 consumer 所分配的 partitions 重新分配,并使得消息可以继续得以消费。
Kafka Consumer Rebalance 过程
- Coordinator 通过在 HeartbeatResponse 中返回 IllegalGeneration 错误码发起 Rebalance 操作。
- Consumer 发送 JoinGroupRequest
- Coordinator 在 Zookeeper 中增加 Group 的 Generation ID 并将新的 Partition 分配情况写入 Zookeeper
- Coordinator 发送 JoinGroupResponse
综上所述,如果 Consumer宕机。我们可以假设 Consumer 与 Coordinator 网络请求耗时 = Ti,本地操作用时忽略不计,则一次 rebalance 从某个 consumer 宕机到整个 rebalance 完成的最大可能时长为:
R = session.timeout.ms + heartbeat.interval.ms + max{Ti}
在此期间,宕机的 consumer 所被分配到的 partitions 的消息无法被处理,直至 rebalance 完成后,迟滞的消息将由新的 consumer 处理。
Rebalance 相关内容参考
- https://stackoverflow.com/questions/43991845/kafka10-1-heartbeat-interval-ms-session-timeout-ms-and-max-poll-interval-ms
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-62%3A+Allow+consumer+to+send+heartbeats+from+a+background+thread
- http://www.infoq.com/cn/articles/kafka-analysis-part-4?utm_source=infoq&utm_campaign=user_page&utm_medium=link
- https://github.com/apache/kafka/tree/0.11.0
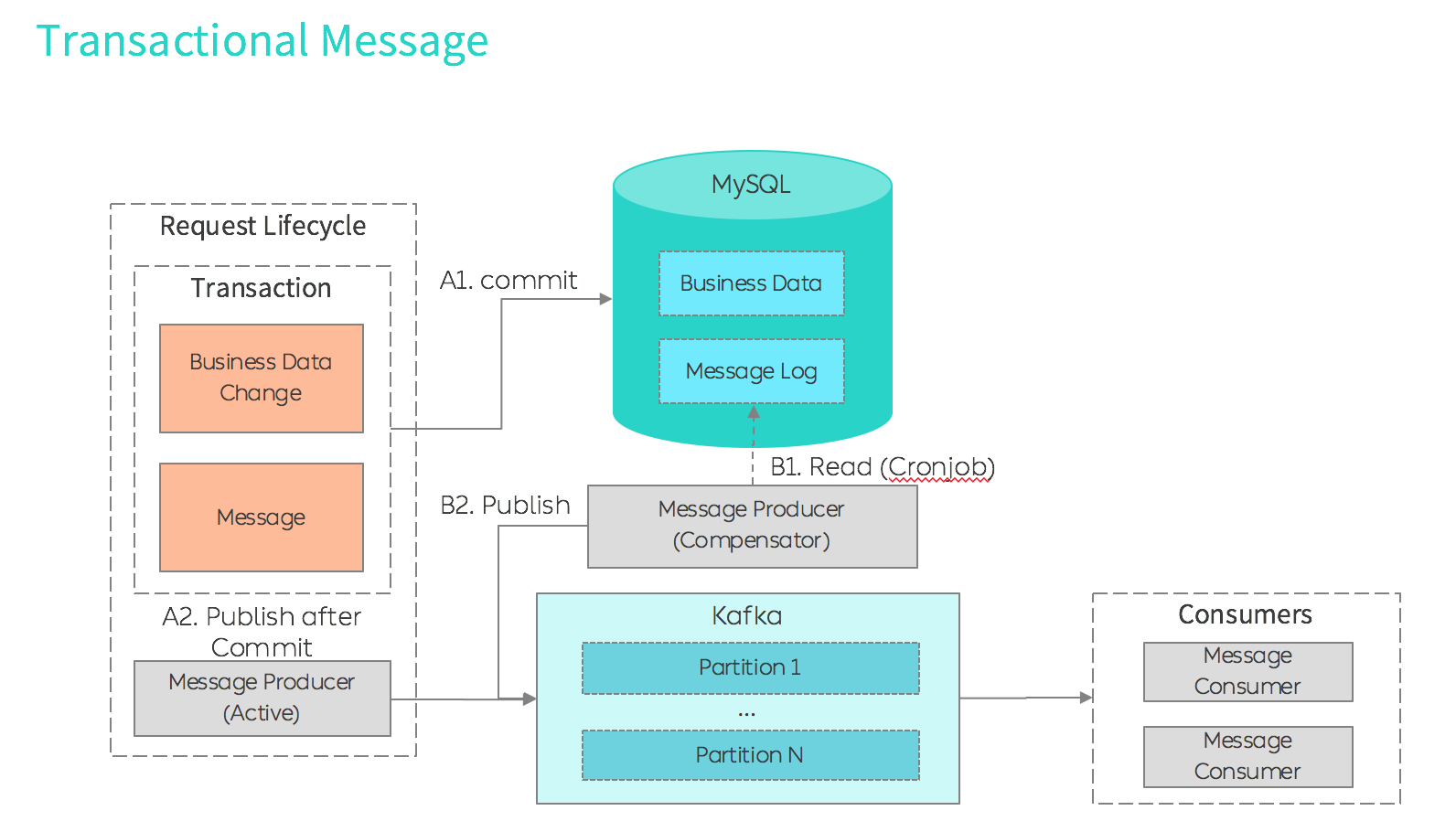
事务型消息
对需要进行业务解耦,要求业务状态消息更新高可靠性的系统,需要有一个能确保业务数据状态、消息发送成功一致性的消息队列,来进行业务解耦。与之对应,消息需要完成以下核心功能:
- Producer: 若业务状态变化了,则与之相关的对应消息最终会被发送成功。
- Message Broker:acks = all
- Consumer: 当消息没有被成功消费时,需要被记录并再次消费。
实现 Producer 事务性的方式:
- 【A1】将 业务改动 和 消息日志记录落库 放在同一个事务中(留痕迹后再进行发送)。
- 【B1/B2】消息的可靠发送:每个 MQ 实例中,会用一个 deamon 会不断地轮训一段时间内应被发送但未发送成功的消息(带重试次数)
- 【A2】提高消息的实时性的方法:状态和消息一起 Commit 以后,在业务代码中的 After Commit 动作中里,自行读取消息进行发送。